RAship Code
Acknowledgements
The following is an R project I developed to perform data analysis on historic economic data for my position as a Research Assistant for Prof. Nicolas Schmitt at Simon Fraser University. The version of this file published on Github will load redacted versions of proprietary data. All categorical variables are aliased, and all numeric fields are shuffled at random to preserve confidentiality. File names and headers are kept the same.
Note from the future: If I were to tackle this project today I would approach the task much differently: I would employ a more conrete naming convention for variables and files, use version control, and would overall use more functions for DRYer code. I include this project here because it served as an important learning opportunity for me, and demonstrates that I’ve solved a real-world assignment.
Data Processing
rm(list=ls()) #clear environment
#load libraries
library(purrr)
library(writexl)
library(openxlsx)
library(readxl)
library(tidyverse)
library(graphics)
library(ggthemes)
library(outliers)
library(ggplot2)
library(plyr)
library(dplyr)
library(ggforce)
library(ggrepel)
library(hexbin)
library(latex2exp)
library(rmarkdown)Summarizing Function: Recategorized Data
nameG <- paste("Cat", seq(1,17), sep = ".")
recatData <- function(file_path) { #defining summary function
data <- read_excel(file_path)
data$Category <- as.factor(data$Category)
data$`General Import Tax` <- sample(data$`General Import Tax`) #randomizing values
data_summary <- data %>%
group_by(Category) %>%
summarise_at(vars(`General Import Tax`), list(mean=mean, sd=sd)) %>%
as.data.frame()
data_count <- data %>% dplyr::count(Category)
data_merged <- left_join(data_summary, data_count, by= 'Category')
levels(data_merged$Category) <- nameG
return(data_merged[-c(17), ])
}1902
oTwoDF <- recatData("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1902_Recat_V3.xlsx")
head(oTwoDF) # example of year = 1902## Category mean sd n
## 1 Cat.1 32.24651 56.68118 129
## 2 Cat.2 51.88235 101.51224 17
## 3 Cat.3 27.00161 32.95000 31
## 4 Cat.4 67.33871 106.33315 31
## 5 Cat.5 24.38889 39.31782 18
## 6 Cat.6 39.35234 79.68471 641891
nineOneDF <- recatData("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1891_Recat_V2.xlsx")
head(nineOneDF) # example of year = 1891## Category mean sd n
## 1 Cat.1 31.44384 55.13447 73
## 2 Cat.2 29.25000 39.12935 14
## 3 Cat.3 20.35000 33.41192 24
## 4 Cat.4 13.50769 15.91035 13
## 5 Cat.5 15.30714 24.42592 7
## 6 Cat.6 22.79333 32.87008 301887
eightSevDF <-recatData("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1891_Recat_V2.xlsx")
head(eightSevDF)## Category mean sd n
## 1 Cat.1 32.47260 65.17196 73
## 2 Cat.2 30.52143 39.16315 14
## 3 Cat.3 25.12500 41.59255 24
## 4 Cat.4 27.08462 41.09249 13
## 5 Cat.5 34.92857 65.38376 7
## 6 Cat.6 30.63500 39.58481 301884
eightFourDF <- recatData("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1884_Recat_V2.xlsx")
head(eightFourDF)## Category mean sd n
## 1 Cat.1 15.73359 21.27716 78
## 2 Cat.2 10.60417 10.90530 12
## 3 Cat.3 16.12500 22.99966 26
## 4 Cat.4 17.49167 18.87497 12
## 5 Cat.5 15.11111 14.17475 9
## 6 Cat.6 17.26167 24.61115 301851_accepted
fiveOneDF <- recatData("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1851_accepted_Recat_V3.xlsx")
head(fiveOneDF)## Category mean sd n
## 1 Cat.1 4.3239130 4.6650800 46
## 2 Cat.2 4.2115385 4.4371610 13
## 3 Cat.3 0.9384615 0.8677446 13
## 4 Cat.4 6.7083333 5.4369492 6
## 5 Cat.5 4.7100000 6.1842946 5
## 6 Cat.6 5.2285714 5.8470477 141849
fourNine <- read_excel("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1849_Recat_V4.xlsx")
fourNine$Category<-as.factor(fourNine$Category)
#converting Batz to Franc
fourNine <- fourNine %>%
mutate(`General Import Tax` = Batz / 7)
fourNine$`General Import Tax` <- sample(fourNine$`General Import Tax`) #randomizing values
fourNineT <- fourNine %>%
group_by(Category) %>%
summarise_at(vars(`General Import Tax`), list(mean=mean, sd=sd)) %>%
as.data.frame()
fourNineN <- fourNine %>% dplyr::count(Category)
fourNineDF <- left_join(fourNineT, fourNineN, by= join_by(Category))
levels(fourNineDF$Category) <- nameG
fourNineDF <- fourNineDF[-c(17), ]Creating Nominal Master Data Frame: 1902, 1891, 1887, 1884, 1851, and 1849
## Master DF... needs to be pivoted
{ppp <- left_join(oTwoDF, nineOneDF, by = join_by(Category));
Tppp <- left_join(ppp, eightSevDF, by = join_by(Category));
Cppp <- left_join(Tppp, eightFourDF, by = join_by(Category));
Gppp <- left_join(Cppp, fiveOneDF, by = join_by(Category));
Qppp<- left_join(Gppp, fourNineDF, by = join_by(Category));
}
## Pivoting Master DF long...
# Pivoting Mean
{mmm = subset(Qppp, select = c(Category, mean.x, mean.y, mean.x.x, mean.y.y, mean.x.x.x, mean.y.y.y));
mmm <- mmm %>%
pivot_longer(cols=-Category, names_to = 'Year', names_prefix = 'mean.', values_to = "mean");
mmm$Year[mmm$Year == "x"] = "1902"; mmm$Year[mmm$Year == "y"] = "1891";
mmm$Year[mmm$Year == "x.x"] = "1887"; mmm$Year[mmm$Year == "y.y"] = "1884"; mmm$Year[mmm$Year == "x.x.x"]="1851";
mmm$Year[mmm$Year == "y.y.y"]="1849"
}
# Pivoting SD
{sdDF = subset(Qppp, select = c(Category, sd.x, sd.y, sd.x.x, sd.y.y, sd.x.x.x, sd.y.y.y));
sdDF <- sdDF %>%
pivot_longer(cols=-Category, names_to = 'Year', names_prefix = 'sd.', values_to = "sd");
sdDF$Year[sdDF$Year == "x"] = "1902"; sdDF$Year[sdDF$Year == "y"] = "1891"; sdDF$Year[sdDF$Year == "sd"] = "1887" ;
sdDF$Year[sdDF$Year == "x.x"] = "1887"; sdDF$Year[sdDF$Year == "y.y"] = "1884"; sdDF$Year[sdDF$Year == "x.x.x"] = "1851";
sdDF$Year[sdDF$Year == "y.y.y"]="1849"
}
# Pivoting n
{nDF = subset(Qppp, select = c(Category, n.x, n.y, n.x.x, n.y.y, n.x.x.x, n.y.y.y));
nDF <- nDF %>%
pivot_longer(cols=-Category, names_to = 'Year', names_prefix = 'n.', values_to = "n")
nDF$Year[nDF$Year == "x"] = "1902"; nDF$Year[nDF$Year == "y"] = "1891"; nDF$Year[nDF$Year == "n"] = "1887";
nDF$Year[nDF$Year == "x.x"] = "1887"; nDF$Year[nDF$Year == "y.y"] = "1884"; nDF$Year[nDF$Year == "x.x.x"] = "1851";
nDF$Year[nDF$Year == "y.y.y"] = "1849"
}
# joining long-pivoted DFs into final DF
fDFt <- left_join(mmm, sdDF, by= join_by(Category, Year))
fDF <- left_join(fDFt, nDF, by= join_by(Category, Year))
fDF[is.na(fDF)] <- 0 # Final Dataframe: "fDF"# Optional code to write to xlsx file
#Write to excel file (warning: will overwrite file with same name. Make sure to change name and path)
#write_xlsx(fDF, "D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1902-1849 Master - Real_V2.xlsx")Real Values
Accounting for a price index; Without accounting for index = “Nominal values”
nameG <- paste("Cat", seq(1,17), sep = ".")
realData <- function(df) { #defining summary function
data <- df
data$Category <- as.factor(data$Category)
data$`General Import Tax` <- sample(data$`General Import Tax`) #randomizing values
data_summary <- data %>%
group_by(Category) %>%
summarise_at(vars(`General Import Tax`), list(mean=mean, sd=sd)) %>%
as.data.frame()
data_count <- data %>% dplyr::count(Category)
data_merged <- left_join(data_summary, data_count, by= 'Category')
levels(data_merged$Category) <- nameG
return(data_merged[-c(17), ])
}
nineOneR <- read_xlsx("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1891_Recat_V2.xlsx") %>%
mutate(`General Import Tax` = `General Import Tax` / 1.048)
eightSevR <- read_xlsx("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1887_Recat_V2.xlsx") %>%
mutate(`General Import Tax` = `General Import Tax` / .922)
eightFourR <- read_xlsx("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1884_Recat_V2.xlsx") %>%
mutate(`General Import Tax` = `General Import Tax` / 1.051)
fiveOneR <- read_xlsx("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1851_accepted_Recat_V3.xlsx") %>%
mutate(`General Import Tax` = `General Import Tax` / 0.864)
fourNineR <- read_xlsx("D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1849_Recat_V4.xlsx") %>%
mutate(`General Import Tax` = Batz / 7)%>%
mutate(`General Import Tax` = `General Import Tax` / 0.745)
RnineOneDF <- realData(nineOneR)
ReightSevDF <- realData(eightSevR)
ReightFourDF <- realData(eightFourR)
RfiveOneDF <- realData(fiveOneR)
RfourNineDF <- realData(fourNineR)Creating Real Master Data Frame: 1902, 1891, 1887, 1884, 1851, and 1849
## Master DF... needs to be pivoted
{Rppp <- left_join(oTwoDF, RnineOneDF, by = join_by(Category));
TRppp <- left_join(Rppp, ReightSevDF, by = join_by(Category));
CRppp <- left_join(TRppp, ReightFourDF, by = join_by(Category));
GRppp <- left_join(CRppp, RfiveOneDF, by = join_by(Category));
QRppp<- left_join(GRppp, RfourNineDF, by = join_by(Category));
}
## Pivoting Master DF long...
# Pivoting Mean
{Rmmm = subset(QRppp, select = c(Category, mean.x, mean.y, mean.x.x, mean.y.y, mean.x.x.x, mean.y.y.y));
Rmmm <- Rmmm %>%
pivot_longer(cols=-Category, names_to = 'Year', names_prefix = 'mean.', values_to = "mean");
Rmmm$Year[Rmmm$Year == "x"] = "1902"; Rmmm$Year[Rmmm$Year == "y"] = "1891";
Rmmm$Year[Rmmm$Year == "x.x"] = "1887"; Rmmm$Year[Rmmm$Year == "y.y"] = "1884"; Rmmm$Year[Rmmm$Year == "x.x.x"]="1851";
Rmmm$Year[Rmmm$Year == "y.y.y"]="1849"
}
# Pivoting SD
{RsdDF = subset(QRppp, select = c(Category, sd.x, sd.y, sd.x.x, sd.y.y, sd.x.x.x, sd.y.y.y));
RsdDF <- RsdDF %>%
pivot_longer(cols=-Category, names_to = 'Year', names_prefix = 'sd.', values_to = "sd");
RsdDF$Year[RsdDF$Year == "x"] = "1902"; RsdDF$Year[RsdDF$Year == "y"] = "1891"; RsdDF$Year[RsdDF$Year == "sd"] = "1887" ;
RsdDF$Year[RsdDF$Year == "x.x"] = "1887"; RsdDF$Year[RsdDF$Year == "y.y"] = "1884"; RsdDF$Year[RsdDF$Year == "x.x.x"] = "1851";
RsdDF$Year[RsdDF$Year == "y.y.y"]="1849"
}
# Pivoting n
{RnDF = subset(QRppp, select = c(Category, n.x, n.y, n.x.x, n.y.y, n.x.x.x, n.y.y.y));
RnDF <- RnDF %>%
pivot_longer(cols=-Category, names_to = 'Year', names_prefix = 'n.', values_to = "n")
RnDF$Year[RnDF$Year == "x"] = "1902"; RnDF$Year[RnDF$Year == "y"] = "1891"; RnDF$Year[RnDF$Year == "n"] = "1887";
RnDF$Year[RnDF$Year == "x.x"] = "1887"; RnDF$Year[RnDF$Year == "y.y"] = "1884"; RnDF$Year[RnDF$Year == "x.x.x"] = "1851";
RnDF$Year[RnDF$Year == "y.y.y"] = "1849"
}
# joining long-pivoted DFs into final DF
RfDFt <- left_join(Rmmm, RsdDF, by= join_by(Category, Year))
RealfDF <- left_join(RfDFt, RnDF, by= join_by(Category, Year))
RealfDF[is.na(RealfDF)] <- 0 # Final Dataframe: "fDF"# Optional code to write to xlsx file
#Write to excel file (warning: will overwrite file with same name. Make sure to change name and path)
#write_xlsx(fDF, "D:\\Everything\\School\\RA position\\Tariff Schedules\\Analysis\\Sector Recategorization\\1902-1849 Master - Real_V2.xlsx")Graphs
The % change of the number of items in each category over consecutive years: \(\frac{(p_{it}-p_{it-1})}{p_{it-1}}\cdot 100\%\)
fDF <- fDF %>%
arrange(Category, Year) %>%
ungroup()
n_percentage_change_df <- fDF %>%
group_by(Category) %>%
mutate(n_Percentage_Change = (n - lag(n)) / lag(n) * 100) %>%
mutate(n_Percentage_Change = ifelse(Year == 1849, NA, n_Percentage_Change)) %>% #setting all 1849 rows to NA to be removed later
ungroup()
n_percentage_change_df <- na.omit(n_percentage_change_df) #removing all 1849 rows because they have no previous year to be compared to
# Histogram
ggplot(n_percentage_change_df , aes(x=Category, y=n_Percentage_Change, group=Year)) +
geom_bar(stat="identity", aes(fill=Year), size=2, position="dodge")+
#geom_errorbar(aes(fill= Year, ymin= ifelse(mean-sd < 0, 0, mean-sd), ymax=mean+sd), position= "dodge") +
geom_point(size=2, position= position_dodge(width=0.9))+
#theme_economist()+
scale_x_discrete(labels=reCatLabs)+
labs(x="", y="% Change in 'n'")+
ggtitle(TeX("Difference in Category(i) n-values over consecutive Years (t): $\\frac{(n_{it}-n_{it-1})}{n_{it-1}}\\cdot 100$"))+ # edit graph title
geom_text(data = n_percentage_change_df, aes(label = round(n_Percentage_Change, 1)),
position = position_dodge(width = 0.9), vjust = -0.25)/Proportional observation differences over consecutive years.jpeg)
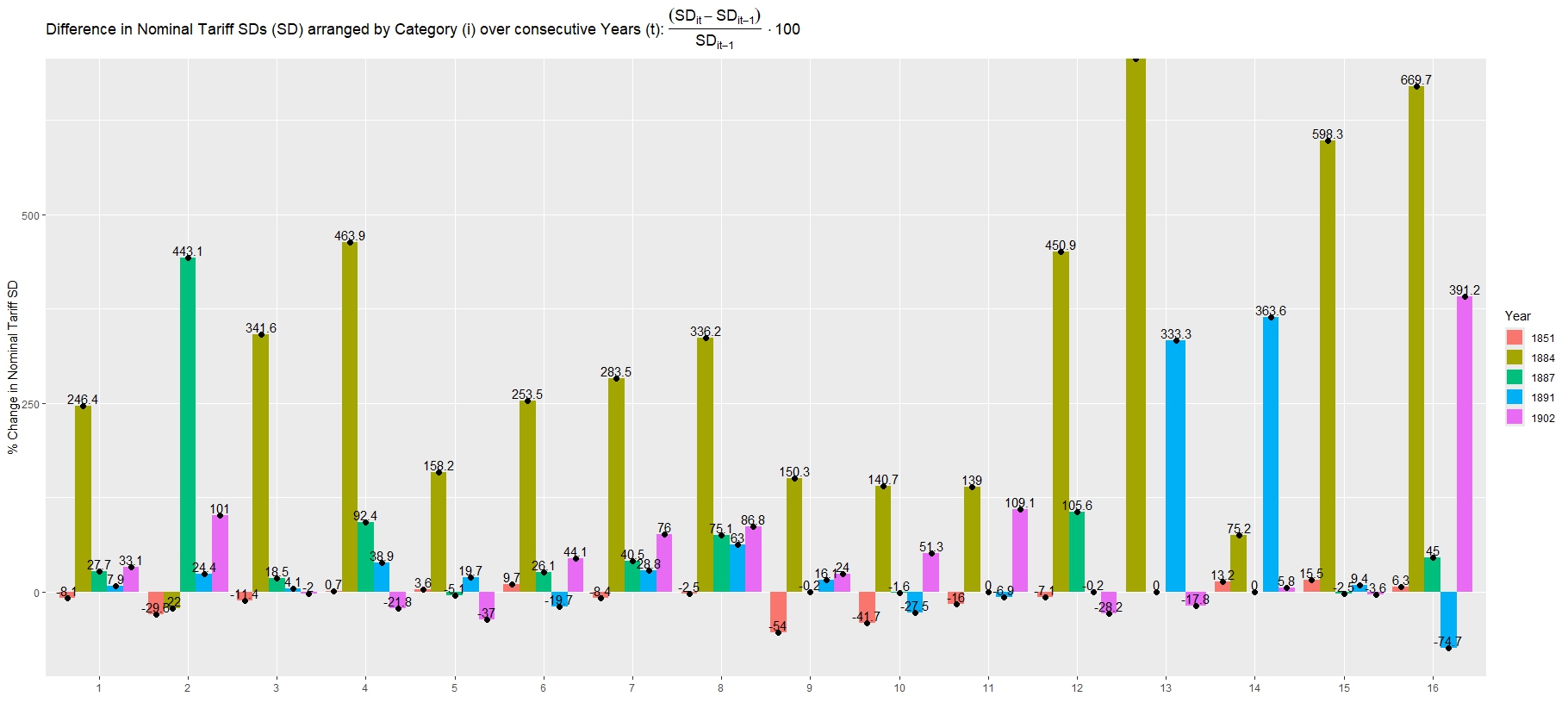
The % change in Tariff SDs over consecutive years: [(SD_(it)-SD_(it-1))/SD_(it-1)]*100
(make sure: are you using REAL or NOMINAL tariffs?)
fDF <- fDF %>%
arrange(Category, Year) %>%
ungroup()
realSD_change_df <- fDF %>%
group_by(Category) %>%
mutate(realSD_Percentage_Change = (sd - lag(sd)) / lag(sd) * 100) %>%
mutate(realSD_Percentage_Change = ifelse(Year == 1849, NA, realSD_Percentage_Change)) %>% #setting all 1849 rows to NA to be removed later
ungroup()
realSD_change_df <- na.omit(realSD_change_df)
# Histogram
ggplot(realSD_change_df , aes(x=Category, y=realSD_Percentage_Change, group=Year)) +
geom_bar(stat="identity", aes(fill=Year), size=2, position="dodge")+
#geom_errorbar(aes(fill= Year, ymin= ifelse(mean-sd < 0, 0, mean-sd), ymax=mean+sd), position= "dodge") +
geom_point(size=2, position= position_dodge(width=0.9))+
#theme_economist()+
scale_x_discrete(labels=reCatLabs)+
labs(x="", y="% Change in Nominal Tariff SD")+
ggtitle(TeX("Difference in Nominal Tariff SDs (SD) arranged by Category (i) over consecutive Years (t): $\\frac{(SD_{it}-SD_{it-1})}{SD_{it-1}}\\cdot 100$"))+ # edit graph title
geom_text(data = realSD_change_df, aes(label = round(realSD_Percentage_Change, 1)),
position = position_dodge(width = 0.9), vjust = -0.25)